
Dữ liệu tổng hợp (Synthetic Data) mang lại nhiều lợi ích cho các tổ chức. Vậy, dữ liệu tổng hợp là gì, được sử dụng trong những trường hợp nào?

Mức độ phổ biến của dữ liệu tổng hợp ngày càng cao nhờ vào ưu điểm tiết kiệm chi phí sản xuất, hỗ trợ phát triển mô hình trí tuệ nhân tạo/học sâu, hay thử nghiệm phần mềm.
Với tính bảo mật cao, dữ liệu tổng hợp cho phép doanh nghiệp tiến hành xây dựng phần mềm mà không để lộ dữ liệu người dùng.
1. Synthetic Data là gì?
Dữ liệu tổng hợp (Synthetic Data) là thông tin được sản xuất một cách nhân tạo bởi thuật toán, chứ không phải bởi sự kiện trong thế giới thực.
Trong khi việc thu thập dữ liệu chất lượng cao từ thế giới thực là khó khăn, tốn kém và mất thời gian, công nghệ dữ liệu tổng hợp cho phép tạo dữ liệu một cách nhanh chóng, dễ dàng và số hóa với bất kỳ số lượng nào họ mong muốn, được tùy chỉnh theo nhu cầu cụ thể.
2. Tại sao dữ liệu tổng hợp lại quan trọng?
Việc sử dụng dữ liệu tổng hợp đang được chấp nhận rộng rãi vì nó mang lại nhiều lợi ích so với dữ liệu trong thế giới thực. Gartner dự đoán rằng, năm 2024, 60% dữ liệu được sử dụng để phát triển trí tuệ nhân tạo (AI - Artificial Intelligence) và phân tích sẽ được sản xuất một cách nhân tạo.
Ứng dụng lớn nhất của dữ liệu tổng hợp là trong việc đào tạo mạng lưới thần kinh và mô hình học máy (ML - machine learning), vì các nhà phát triển những mô hình này cần bộ dữ liệu được dán nhãn cẩn thận, dao động từ vài nghìn đến hàng chục triệu mục.
Synthetic Data hướng tới khả năng bắt chước tập dữ liệu thực, cho phép tổ chức tạo ra lượng dữ liệu đào tạo lớn và đa dạng mà không tốn nhiều chi phí cũng như thời gian.
Dữ liệu tổng hợp cũng được sử dụng để bảo vệ quyền riêng tư của người dùng và tuân thủ vấn đề pháp lý, đặc biệt là trong xử lý dữ liệu nhạy cảm, chẳng hạn như thông tin cá nhân và sức khỏe.
Ngoài ra, nó có thể được sử dụng để giảm bớt sự thiên vị bằng cách đảm bảo rằng mô hình đào tạo và người dùng có quyền truy cập vào tập dữ liệu đa dạng, mô tả chính xác thế giới thực.
3. Dữ liệu tổng hợp được tạo ra như thế nào?
Quá trình tạo dữ liệu tổng hợp khác nhau tùy theo công cụ và thuật toán cũng như trường hợp sử dụng cụ thể. 3 kỹ thuật phổ biến được sử dụng để tạo dữ liệu tổng hợp bao gồm:
Phân phối thống kê (Drawing numbers from a distribution)
Chọn ngẫu nhiên các số từ phân phối là phương pháp phổ biến để tạo dữ liệu tổng hợp. Mặc dù phương pháp này không nắm bắt được những hiểu biết sâu sắc về dữ liệu trong thế giới thực, nhưng nó có thể tạo ra sự phân bổ dữ liệu gần giống với dữ liệu thực tế.
Mô hình dựa trên agent (Agent-based modeling)
Kỹ thuật mô phỏng này liên quan đến việc tạo ra những tác nhân (agent) duy nhất có thể giao tiếp với nhau. Phương pháp này đặc biệt hữu ích khi kiểm tra cách các agent khác nhau, chẳng hạn như điện thoại di động, con người hoặc thậm chí chương trình máy tính, tương tác với nhau trong một hệ thống phức tạp.
Sử dụng thành phần cốt lõi dựng sẵn, các gói Python như Mesa, giúp việc phát triển mô hình dựa trên agent nhanh chóng và việc quan sát chúng qua giao diện dựa trên trình duyệt trở nên dễ dàng hơn.
Mô hình tạo sinh (Generative models)
Thuật toán này có thể tạo ra dữ liệu tổng hợp sao chép các thuộc tính hoặc tính năng thống kê của dữ liệu trong thế giới thực.
Mô hình tạo sinh sử dụng một tập hợp dữ liệu huấn luyện để tìm hiểu các mẫu thống kê và mối quan hệ trong dữ liệu, sau đó sử dụng kiến thức này để tạo ra dữ liệu tổng hợp mới tương tự như dữ liệu gốc.
Xem thêm bài viết: Generative AI là gì? Ứng dụng và ảnh hưởng AI tạo sinh
Ví dụ về mô hình tạo sinh bao gồm mạng đối nghịch tạo sinh (GAN) và bộ mã hóa tự động biến đổi (VAE).
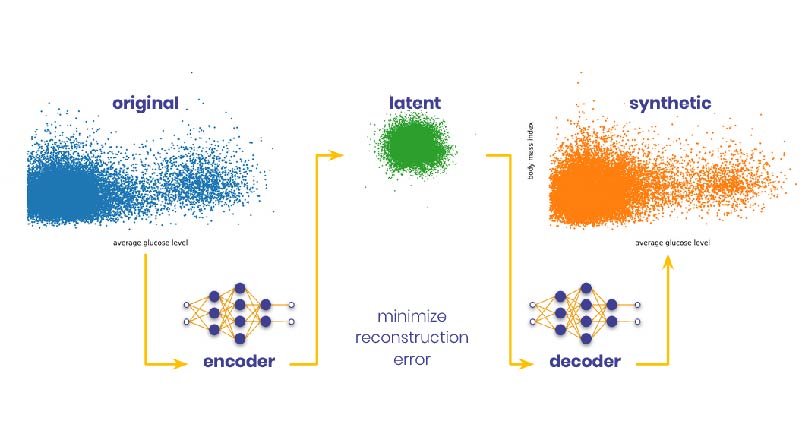
Quy trình tạo dữ liệu tổng hợp từ VAE - Ảnh: Internet
4. Lợi ích từ dữ liệu tổng hợp
Dữ liệu tổng hợp có nhiều ưu điểm khi ứng dụng trong thực tiễn, bao gồm:
Khả năng tùy chỉnh: Tổ chức có thể tùy chỉnh dữ liệu tổng hợp sao cho phù hợp với nhu cầu của mình, theo những điều kiện nhất định mà dữ liệu thực tế không thể có được.
Tiết kiệm chi phí: Dữ liệu tổng hợp là một giải pháp thay thế chi phí thấp cho dữ liệu trong thế giới thực.
Ghi nhãn dữ liệu: Ngay cả khi có sẵn dữ liệu tổng hợp, không phải lúc nào nó cũng được dán nhãn. Đối với nhiệm vụ học có giám sát, việc gắn nhãn thủ công cho nhiều phiên bản có thể tốn thời gian và dễ xảy ra lỗi. Dữ liệu tổng hợp gắn nhãn được tạo để tăng tốc quá trình phát triển mô hình, đồng thời đảm bảo nhãn gắn chính xác.
Sản xuất nhanh hơn: Vì dữ liệu tổng hợp không được thu thập từ sự kiện thực tế nên tạo tập dữ liệu cũng diễn ra nhanh hơn bằng cách sử dụng phần mềm và công nghệ phù hợp.
Đầy đủ chú thích: Chú thích giúp loại bỏ nhu cầu thu thập dữ liệu thủ công. Mỗi đối tượng trong một sự kiện có thể tự động tạo ra nhiều chú thích khác nhau. Đây cũng là một trong những lý do chính khiến dữ liệu tổng hợp có chi phí thấp hơn so với dữ liệu thực.
Quyền riêng tư dữ liệu: Mặc dù dữ liệu tổng hợp có thể giống với dữ liệu thực, nhưng nó không được chứa bất kỳ thông tin nhạy cảm nào. Đặc điểm này làm cho dữ liệu tổng hợp trở nên ẩn danh và phù hợp để phổ biến rộng rãi.
Kiểm soát người dùng: Mô phỏng dữ liệu tổng hợp cho phép kiểm soát hoàn toàn mọi khía cạnh.
Ngoài những ưu điểm nổi bật, dữ liệu tổng hợp cũng có một số nhược điểm, bao gồm sự không nhất quán khi cố gắng tái tạo độ phức tạp tương tự tập dữ liệu gốc, cũng như không thể thay thế hoàn toàn dữ liệu thực tế.
5. Trường hợp sử dụng dữ liệu tổng hợp
Các trường hợp sử dụng điển hình cho dữ liệu tổng hợp bao gồm:
Thử nghiệm
So với dữ liệu thử nghiệm dựa trên quy tắc (rules-based test data), dữ liệu thử nghiệm tổng hợp dễ tạo hơn và mang lại tính linh hoạt, khả năng mở rộng và tính chân thực. Đối với thử nghiệm dựa trên dữ liệu và phát triển phần mềm, dữ liệu tổng hợp là rất quan trọng.
Đào tạo mô hình AI/ML
Dữ liệu tổng hợp ngày càng được sử dụng nhiều để huấn luyện mô hình AI, vì nó thường hoạt động tốt hơn dữ liệu trong thế giới thực.
Hiệu suất của mô hình được nâng cao nhờ dữ liệu đào tạo tổng hợp, điều này cũng giúp loại bỏ sự thiên vị, bổ sung thêm kiến thức và khả năng giải thích về lĩnh vực mới. Bên cạnh việc hoàn toàn tuân thủ quyền riêng tư, nó còn nâng cao dữ liệu gốc nhờ bản chất của quy trình tạo sinh do AI cung cấp.
Quy định về quyền riêng tư
Dữ liệu tổng hợp cho phép nhà khoa học dữ liệu tuân thủ luật về quyền riêng tư dữ liệu, chẳng hạn như theo Đạo luật về trách nhiệm giải trình và cung cấp thông tin bảo hiểm y tế, Quy định chung về bảo vệ dữ liệu và Đạo luật về quyền riêng tư của người tiêu dùng California.
Đây cũng là lựa chọn tốt nhất khi sử dụng những tập dữ liệu nhạy cảm để thử nghiệm hoặc đào tạo. Dữ liệu tổng hợp cho phép tổ chức có thêm hiểu biết sâu sắc về một vấn đề nào đó mà không ảnh hưởng đến việc tuân thủ quyền riêng tư.
6. Ứng dụng của Synthetic Data
Dữ liệu tổng hợp được ứng dụng ở nhiều ngành khác nhau cho những trường hợp sử dụng khác nhau, bao gồm:
Dữ liệu truyền thông: Đồ họa máy tính và thuật toán xử lý hình ảnh được sử dụng để tạo ra hình ảnh, âm thanh và video. Ví dụ, Amazon sử dụng dữ liệu tổng hợp để đào tạo hệ thống ngôn ngữ Amazon Alexa.
Dữ liệu văn bản: Bao gồm chatbot, thuật toán dịch máy (machine translation) và phân tích tình cảm dựa trên dữ liệu văn bản nhân tạo. ChatGPT là một ví dụ về công cụ sử dụng dữ liệu văn bản.
Dữ liệu dạng bảng: Các bảng dữ liệu nhân tạo được sử dụng trong phân tích dữ liệu, đào tạo mô hình và nhiều ứng dụng khác.
Dữ liệu phi cấu trúc: Có thể bao gồm dữ liệu hình ảnh, video và âm thanh được sử dụng chủ yếu trong các lĩnh vực như thị giác máy tính, nhận dạng giọng nói và công nghệ xe tự hành.
Dữ liệu dịch vụ tài chính: Lĩnh vực tài chính phụ thuộc rất nhiều vào dữ liệu tổng hợp, đặc biệt là để phát hiện gian lận, quản lý rủi ro và đánh giá rủi ro tín dụng.
Dữ liệu sản xuất: Ngành sản xuất sử dụng dữ liệu tổng hợp để kiểm soát chất lượng và bảo trì dự đoán.
Dịch vụ tài chính và chăm sóc sức khỏe là hai ngành được hưởng lợi nhiều nhất từ kỹ thuật dữ liệu tổng hợp. Kỹ thuật này có thể được sử dụng để tạo ra dữ liệu có thuộc tính tương tự như dữ liệu nhạy cảm hoặc được quản lý thực tế. Điều này cho phép các chuyên gia dữ liệu sử dụng và chia sẻ dữ liệu một cách tự do hơn.
Trong chăm sóc sức khỏe, dữ liệu tổng hợp giúp chuyên gia sử dụng công khai dữ liệu ở cấp độ hồ sơ nhưng vẫn duy trì tính bảo mật của bệnh nhân.
Trong lĩnh vực tài chính, các bộ dữ liệu tổng hợp, chẳng hạn như thanh toán bằng thẻ ghi nợ và thẻ tín dụng, hoạt động như dữ liệu giao dịch thông thường có thể giúp vạch trần hành vi gian lận.
Nhà khoa học dữ liệu sử dụng dữ liệu tổng hợp để kiểm tra hoặc đánh giá hệ thống phát hiện gian lận, cũng như phát triển phương pháp cảnh báo mới. Trong khi đó, nhóm DevOps sử dụng dữ liệu tổng hợp để kiểm tra phần mềm và quản lý chất lượng.
Một số ứng dụng khác của dữ liệu tổng hợp - Ảnh: Internet
Dữ liệu tổng hợp đóng vai trò quan trọng trong việc thay thế dữ liệu thực, nhằm cải thiện mô hình AI, bảo vệ dữ liệu nhạy cảm và giảm thiểu sai lệch. Hy vọng thông qua bài viết của Elcom, bạn đọc sẽ có cái tổng quan hơn về dữ liệu tổng hợp và những lợi ích kỹ thuật này mang lại.
Nguồn tham khảo:
https://www.techtarget.com/searchcio/definition/synthetic-data
![[ELCOM ITS] Inside ELCOM ITS: Cách các hệ thống giao thông thông minh được tạo ra](https://elcom.com.vn/storage/uploads/images/T9bk59vjsZOeOLnZd6MTL9aIlD8hjfdts1x0BhFU.png)
![[ELCOM ITS] Toàn cảnh bức tranh giao thông đô thị Việt Nam](https://elcom.com.vn/storage/uploads/images/r39s7ufmcggta29Taw5iGprfb4tMLb2beRmGsSBg.png)
![[ELCOM ITS] Lịch sử ITS Việt Nam: Hành trình thông minh hóa giao thông quốc gia](https://elcom.com.vn/storage/uploads/images/OPLZ1SxPQYi9Dzhztc48h0RHTeo4biTvTEhzBLeW.png)

