
Khoa học dữ liệu và học máy đều đóng vai trò quan trọng trong Trí tuệ nhân tạo, song chúng lại có nhiều điểm khác biệt. Hãy cùng Elcom tìm hiểu về hai lĩnh vực này và ứng dụng của chúng.

Trong những năm gần đây, Trí tuệ nhân tạo (Artificial Intelligence - AI) đã bùng nổ mạnh mẽ hơn bao giờ hết. Kéo theo đó, hai lĩnh vực “con” bao gồm khoa học dữ liệu (Data science) và học máy (Machine learning) cũng nhìn thấy sự tăng trưởng vượt bậc về nhu cầu và phạm vi ứng dụng trong cuộc sống.
Theo ước tính, giá trị thị trường Trí tuệ nhân tạo toàn cầu sẽ đạt gần 2 nghìn tỷ đô la vào năm 2030. Nhu cầu về nhân sự, cụ thể là kỹ sư hay chuyên gia về AI cũng tăng lên với tốc độ tương xứng bởi họ là những người đứng sau sự thành công của ngành công nghiệp này. Đó là lý do các công ty công nghệ luôn cố gắng tạo điều kiện làm việc hấp dẫn và mức lương cạnh tranh để thu hút, giữ chân nhân tài.
Mặc dù khoa học dữ liệu và học máy thường bị nhầm lẫn với nhau bởi đặc điểm chung là làm việc với máy tính và dữ liệu, tuy nhiên chúng lại tập trung vào những mảng riêng biệt, đòi hỏi kỹ năng khác nhau.
Đối với doanh nghiệp coi AI là công nghệ chiến lược để phát triển sản phẩm, việc phân biệt rõ hai mảng này là yếu tố cốt lõi nhằm xây dựng nguồn nhân lực chất lượng cao.
Ngược lại, ứng viên hoặc người muốn tìm công việc trong ngành này cũng cần nắm rõ đâu là các kỹ năng cần thiết cho từng vị trí công việc từ đó dễ dàng phát triển sự nghiệp bản thân.
Xem thêm bài viết:
- Ngành khoa học phân tích dữ liệu học trường nào? Ra trường làm gì?
- Ngành trí tuệ nhân tạo học gì? Học AI ra trường làm gì?
1. Khoa học dữ liệu là gì?
Khoa học dữ liệu (Data science) là một lĩnh vực liên ngành tích hợp nhiều khái niệm và phương pháp từ phân tích dữ liệu, khoa học thông tin, học máy và thống kê.
Nói một cách tổng quát, khoa học dữ liệu hướng tới mục tiêu chắt lọc những dữ liệu, thông tin hữu ích có khả năng thúc đẩy hành động nhằm giải quyết một vấn đề, bài toán cụ thể.
Bằng cách xác định mô hình xu hướng theo thời gian, nhà quản trị tổ chức sẽ đưa ra quyết định thông minh hơn, nâng cao hiệu suất và phát triển chiến lược dựa trên dữ liệu.
1.1 Các bước trong quy trình khoa học dữ liệu
Trước khi đưa vào sử dụng phục vụ mục đích nghiên cứu hoặc ra quyết định của người đứng đầu, dữ liệu phải trải qua những bước sau:
Xác định giả thuyết
Trước khi thực sự bước vào thu thập hoặc phân tích bất kỳ dữ liệu nào, các chuyên gia cần xác định rõ bài toán đặt ra cho mỗi tổ chức, doanh nghiệp. Sau đó, họ phát triển một giả thuyết nhằm kiểm tra tình hình thực tế của bài toán đó.
Thu thập dữ liệu
Dữ liệu có thể thu được từ nhiều nguồn khác nhau ở cả nội bộ lẫn bên ngoài tổ chức như: phần mềm CRM, mạng xã hội, nhật ký hoạt động của máy chủ, hay mua dữ liệu từ bên thứ ba uy tín.
Làm sạch dữ liệu
Đây là bước tốn khá nhiều thời gian bởi dữ liệu cần phải “làm sạch” và chuẩn hóa kỹ lưỡng. Ngoài ra, những dữ liệu này thường nằm rải rác, riêng lẻ, không đồng nhất về định dạng và thiếu giá trị.
Khám phá dữ liệu
Tại đây, dữ liệu được phân tích sơ bộ bằng cách sử dụng thống kê mô tả và trực quan hóa dữ liệu thông qua biểu đồ. Từ đó, các chuyên gia sẽ có cái nhìn tổng quan về tập dữ liệu tổng thể và đặc điểm của nó.
Mô hình hóa dữ liệu
Dữ liệu sẽ trải qua quá trình thử nghiệm quay lại giả thuyết ban đầu để đánh giá tính chính xác của mô hình tạo ra bằng phần mềm và thuật toán học máy như liên kết, phân loại và phân nhóm,…
Báo cáo và trực quan hóa dữ liệu
Đây là bước cuối cùng để vận chuyển dữ liệu tới các bên liên quan như nhà lãnh đạo, cổ đông, nhóm chuyên viên kỹ thuật,… nhằm phục vụ mục đích của họ. Dữ liệu được hiển thị thông qua bảng, biểu đồ, hình ảnh,...
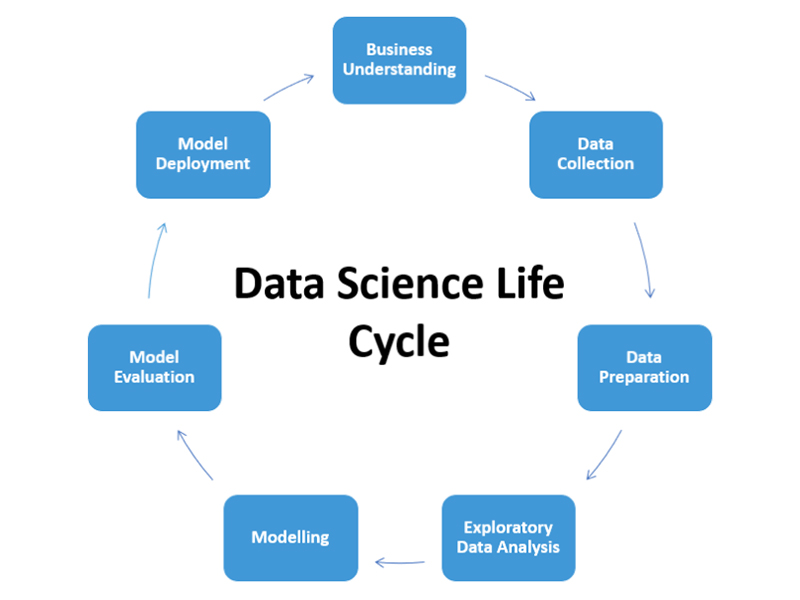
Vòng đời của quy trình khoa học dữ liệu - Nguồn ảnh: Internet
1.2 Ứng dụng phổ biến của khoa học dữ liệu trong các ngành công nghiệp
Bán lẻ
Khoa học dữ liệu giúp phân tích hành vi mua sắm của khách hàng, dự đoán xu hướng sản phẩm, tối ưu hóa quy trình tồn kho. Thông qua việc sử dụng dữ liệu thông minh, doanh nghiệp bán lẻ có thể tạo ra chiến lược tiếp thị thông minh, cải thiện trải nghiệm khách hàng và tăng hiệu suất kinh doanh.
Tài chính - ngân hàng
Tài chính - ngân hàng là một ngành nghề cần sử dụng nhiều dữ liệu, thông tin. Vì vậy, khoa học dữ liệu sẽ cung cấp khả năng phân tích chi tiết, giảm thiểu dữ liệu tài chính phức tạp. Một số ứng dụng có thể kể đến như: Dự đoán và quản lý rủi ro; Phân tích khách hàng; Quản lý dự trữ vốn; Phát hiện gian lận và an ninh tài chính; Tối ưu hóa danh mục đầu tư …

Khoa học dữ liệu được ứng dụng rộng rãi trong lĩnh vực tài chính ngân hàng - Nguồn ảnh: Internet
Sản xuất
Tối ưu hóa quá trình sản xuất là nhiệm vụ quan trọng của ngành này. Ứng dụng khoa học dữ liệu giúp doanh nghiệp dự đoán nhu cầu thị trường, nâng cao chất lượng sản phẩm. Ngoài ra, nó còn hỗ trợ cải thiện hiệu suất máy móc, tối ưu hóa chuỗi cung ứng, giảm lãng phí nguyên vật liệu.
2. Học máy là gì?
Học máy (Machine learning) vừa là một lĩnh vực con của Trí tuệ Nhân tạo (AI), vừa là kỹ thuật được sử dụng trong khoa học dữ liệu. Tại đây, các thuật toán có khả năng phát hiện mẫu và mối liên kết trong dữ liệu, từ đó tự động điều chỉnh hành vi của chúng để cải thiện hiệu suất.
Một khi dữ liệu đã được “dạy” đủ về chất lượng lẫn số lượng, hệ thống máy học có thể đưa ra dự đoán, phân tích phức tạp - thứ mà việc lập trình (code) thủ công không thể làm tốt được.
Thông thường, các chuyên gia hay kỹ sư hướng tới xây dựng hệ thống học máy linh hoạt, đáng tin cậy, có khả năng thích nghi với dữ liệu mới. Mô hình học máy hoàn toàn có khả năng tự động điều chỉnh hành vi của chúng khi tiếp xúc với dữ liệu mới mà không cần sự can thiệp của con người.
Đây cũng chính là điều làm nên sự khác biệt giữa học máy so với nhiều phần mềm truyền thống.

Học máy là một lĩnh vực con của Trí tuệ Nhân tạo (AI) - Nguồn ảnh: Internet
2.1. Quy trình máy học diễn ra như thế nào?
Tương tự như luồng công việc trong khoa học dữ liệu, quy trình học máy cũng bắt đầu từ việc thu thập và xử lý dữ liệu thô. Sau đó, mô hình học máy tiếp nhận vào một tập dữ liệu ban đầu, xác định mẫu cũng như mối quan hệ trong tập dữ liệu đó.
Thông tin thu về sẽ dùng để điều chỉnh biến nội tại, hay còn gọi là tham số. Mô hình này tiếp tục được đánh giá độ chính xác thông qua việc thử nghiệm tập dữ liệu mới để xem cách nó phản ứng với dữ liệu chưa từng thấy trước đây.
Tuy những bước này có vẻ đều rất quen thuộc trong quy trình khoa học dữ liệu, nhưng điểm khác biệt ở đây chính là: Mục đích của khoa học dữ liệu là trình bày kết quả của phân tích cho các bên yêu cầu, trong khi đó mục đích của học máy là triển khai, theo dõi, duy trì mô hình trong quá trình sản xuất.
Giai đoạn triển khai và theo dõi mô hình này tương tự với chu kỳ DevOps cho phần mềm truyền thống. Do đó chúng ta có thuật ngữ "MLOps" (Machine Learning Operations - Quản lý học máy).
Để triển khai một mô hình học máy, cần tích hợp nó vào ứng dụng, phần mềm sản xuất. Trong đó, việc theo dõi, gỡ lỗi, duy trì mô hình sau khi triển khai cần được chú trọng.
Bởi vì tình hình thực tế luôn biến đổi không ngừng, vậy nên nhân sự MLOps cần phải hiệu chỉnh và tái đào tạo các mô hình liên tục, đảm bảo chúng hoạt động hiệu quả qua thời gian.
2.2 Một vài ứng dụng tiêu biểu của Học máy
Giống như khoa học dữ liệu, học máy đóng vai trò quan trọng trong nhiều ngành công nghiệp hiện nay. Thuật toán học máy có thể thực hiện một loạt chức năng liên quan đến mục tiêu kinh doanh (dự đoán, tự động hóa quy trình, tạo nội dung…).
Y tế
Học máy được sử dụng để chẩn đoán bệnh thông qua ảnh chụp y khoa, dự đoán nguy cơ tiềm ẩn, tối ưu hóa lịch trình điều trị, giúp quản lý dữ liệu bệnh nhân một cách hiệu quả.
Từ đó bệnh nhân dễ dàng cải thiện tình trạng sức khỏe, tiết kiệm thời gian đồng thời giảm áp lực về trang thiết bị y tế cần thiết. Đây chính là một bước tiến mới trong quá trình phát triển y tế số của nhiều quốc gia trên thế giới hiện nay.
Xem thêm bài viết: Ý nghĩa của trí tuệ nhân tạo với ngành Y tế - Chăm sóc sức khỏe
Luật pháp
Đối với lĩnh vực pháp luật, học máy giúp tự động hóa quy trình xem xét hồ sơ, tài liệu pháp lý, phân tích hợp đồng, xác định thông tin liên quan trong vụ án, tạo quy trình mẫu cho các tài liệu pháp lý thông thường.
Từ đó năng suất và độ chính xác trong nghiệp vụ của luật sư, thẩm phán,... tăng lên đáng kể, tiết kiệm thời gian, công sức để dành cho những nhiệm vụ cần chú trọng hơn.
Năng lượng
Học máy có thể được sử dụng trong dự đoán, quản lý tiêu thụ năng lượng. Đồng thời chúng còn tối ưu hóa hoạt động của các nguồn năng lượng tái tạo như đường biển gió, năng lượng mặt trời, cải thiện hiệu suất của hệ thống phân phối năng lượng.
Từ đó, việc lãng phí năng lượng giảm thiểu đáng kể, hướng mới mục tiêu phát triển nguồn năng lượng sạch và bền vững.
Giao thông thông minh
Trong quá trình điều khiển giao thông, các đơn vị chức năng có thể ứng dụng công nghệ học máy nhằm dự đoán tình hình giao thông trên tuyến, tối ưu hóa luồng xe cộ, và đảm bảo sự an toàn,… thông qua phân tích dữ liệu từ cảm biến và hệ thống camera AI giám sát.
3. Sự khác biệt giữa khoa học dữ liệu và máy học
Mặc dù khoa học dữ liệu và học máy tương đồng nhau ở nhiều khía cạnh, tuy nhiên hai khái niệm này vẫn có những sự khác biệt đáng chú ý.
Cụ thể, thuật ngữ "học máy" là một phần cụ thể của công nghệ Trí tuệ Nhân tạo (AI). Đồng thời, các mô hình học máy cũng là mảnh ghép quan trọng trong nhiều quy trình khoa học dữ liệu, là công cụ thiết yếu của chuyên gia, kỹ sư khoa học dữ liệu.
Nhưng định nghĩa khoa học dữ liệu lại mang ý nghĩa rộng hơn, như một ngành học không chỉ bao gồm học máy mà còn nhiều công cụ khác như: thống kê, khoa học thông tin, thậm chí là đồ họa,..
Thông thường, các nhà khoa học dữ liệu không trực tiếp triển khai và theo dõi mô hình học máy trong sản xuất như đã đề cập ở phía trên. Trái lại, kỹ sư học máy và MLOps lại yêu cầu trang bị kiến thức về quy trình khoa học dữ liệu, cơ sở hạ tầng công nghệ thông tin, cũng như nắm rõ ứng dụng thực tế của chúng trong các kỹ thuật phần mềm truyền thống/DevOps.
Nguồn tham khảo:
https://www.techtarget.com/searchenterpriseai/feature/Data-science-vs-machine-learning-How-are-they-different
![[ELCOM ITS] Inside ELCOM ITS: Cách các hệ thống giao thông thông minh được tạo ra](https://elcom.com.vn/storage/uploads/images/T9bk59vjsZOeOLnZd6MTL9aIlD8hjfdts1x0BhFU.png)
![[ELCOM ITS] Toàn cảnh bức tranh giao thông đô thị Việt Nam](https://elcom.com.vn/storage/uploads/images/r39s7ufmcggta29Taw5iGprfb4tMLb2beRmGsSBg.png)
![[ELCOM ITS] Lịch sử ITS Việt Nam: Hành trình thông minh hóa giao thông quốc gia](https://elcom.com.vn/storage/uploads/images/OPLZ1SxPQYi9Dzhztc48h0RHTeo4biTvTEhzBLeW.png)

