
Máy học (ML - Machine learning) là lĩnh vực được quan tâm trong nhiều năm gần đây. Hãy cùng tìm hiểu về những thuật ngữ trong học máy phổ biến.
Thuật ngữ học máy/machine learning thường được sử dụng song song với trí tuệ nhân tạo (AI - Artificial Intelligence), học sâu (deep learning) và dữ liệu lớn (big data), thực chất có ý nghĩa gì?
Học máy là gì?
McKinsey đã định nghĩa học máy là “thuật toán có thể học từ dữ liệu mà không cần dựa vào lập trình trên quy tắc”. Đại học Carnegie Mellon ở Pennsylvania cho biết: Lĩnh vực học máy tìm cách trả lời câu hỏi “Làm thế nào xây dựng hệ thống máy tính tự động cải thiện theo kinh nghiệm và quy luật cơ bản chi phối tất cả quá trình học tập là gì?”.
Ứng dụng học máy trong thực tiễn
Học máy có thể hiểu là độ chính xác của hệ thống được cải thiện theo thời gian thông qua bổ sung thêm dữ liệu và phản hồi. Bạn chắc chắn đã gặp nhiều ví dụ về học máy hàng ngày.
Chẳng hạn như, Facebook gợi ý kết bạn với “Những người bạn có thể biết” hoặc Amazon gửi email đề xuất sản phẩm dựa trên những lần mua hàng trước đó. Những nền tảng này đang sử dụng thuật toán học máy để tùy chỉnh kết quả cá nhân hóa.
Học máy đào sâu công việc của trí tuệ nhân tạo. Trong AI, các nhà nghiên cứu ban đầu tạo quy tắc để máy tính đưa ra quyết định. Với học máy, máy tính thực sự “tự học” và thiết kế những quy tắc mới thông qua thực hành, lặp lại và cải tiến.
Từ chẩn đoán y tế đến phát hiện gian lận, học máy đang cải thiện khả năng giải quyết các vấn đề xã hội. Paypal mua lại công ty khởi nghiệp ML Simility nhằm phân tích hàng triệu giao dịch và theo dõi điểm bất thường, giúp ngăn chặn hoạt động rửa tiền.
Học máy cũng có khả năng dự đoán tình trạng mức oxy thấp trong quá trình phẫu thuật; nhận biết nguy cơ tim mạch; xác định sự tăng trưởng bất thường trong cơ thể;...
Việc áp dụng công nghệ này trên quy mô lớn không phải là không có thách thức. Đôi khi rất khó tìm được mẫu dữ liệu đủ lớn để máy đào tạo. Đồng thời, lạm dụng ML cũng không được khuyến khích.
Nhiều người lo lắng về việc ML sẽ thay thế con người. Tuy nhiên, con người và máy móc vẫn bổ sung cho nhau về nhiều mặt. Theo Harvard Business Review: “Thông qua trí tuệ cộng tác, con người và AI tích cực nâng cao các thế mạnh bổ sung cho nhau”.
Xem thêm bài viết: Robot AI có thể thay thế con người trong tương lai?
Con người giúp đào tạo, vận hành máy móc và giải thích hành vi của chúng. Khi Microsoft phát triển ML bot Cortana, dự án yêu cầu những điểm dữ liệu đáng kể và hiểu biết sâu sắc về con người để tạo ra một tính cách “tự tin, quan tâm và hữu ích nhưng không kiêu căng, xa cách”.
Nhóm huấn luyện có một nhà thơ, một tiểu thuyết gia và một nhà viết kịch với nhiệm vụ hỗ trợ robot giao tiếp hiệu quả với con người.
Những thuật ngữ trong học máy thường gặp
Để tìm hiểu sâu hơn về lĩnh vực máy học, trước tiên hãy tìm hiểu những thuật ngữ liên quan:
1. Classification
Classification (Tạm dịch: Phân loại) là một phần của quá trình học có giám sát (học với dữ liệu được dán nhãn). Qua đó, dữ liệu đầu vào dễ dàng phân tách thành nhiều danh mục.
Học máy bao gồm bộ phân loại nhị phân chỉ có hai kết quả (Ví dụ: thư rác, không phải thư rác) hoặc bộ phân loại nhiều lớp (Ví dụ: loại sách, loài động vật,...).
Một trong những thuật toán phân loại phổ biến nhất là cây quyết định (Decision tree), cần thiết cho cả nhà khoa học dữ liệu và kỹ sư máy học. Theo đó, các câu hỏi lặp đi lặp lại dẫn đến phân loại chính xác có thể xây dựng khuôn khổ “nếu-thì” để thu hẹp nhóm khả năng theo thời gian.
Phân loại trong quá trình học máy ứng dụng trong nhiều lĩnh vực đời sống - Ảnh: Internet
2. Clustering
Clustering (Tạm dịch: Phân cụm) là một hình thức học không giám sát (học với dữ liệu không được gắn nhãn), bao gồm việc nhóm các điểm dữ liệu theo tính năng và thuộc tính cụ thể.
Phân cụm được sử dụng để sắp xếp nhân khẩu học và hành vi mua sắm của khách hàng thành những phân khúc khác nhau, từ đó nhắm mục tiêu và định vị sản phẩm.
Clustering có thể phân tích chất lượng nhà ở và vị trí địa lý phục vụ định giá bất động sản và lên kế hoạch bố trí các khu phát triển thành phố mới. Ngoài ra, nó cũng phân loại thông tin theo chủ đề trong thư viện điện tử, trang web và biên soạn thư mục để người dùng thuận tiện truy cập.
Loại phân cụm phổ biến nhất là phân cụm K-means (K-means Clustering), bao gồm việc biểu diễn mỗi cụm bằng một biến “k”, tiếp theo xác định trọng tâm của các cụm đó. Tất cả điểm dữ liệu được gán cho một cụm cụ thể và thông qua quá trình này để xác định tâm của các cụm mới.
Dưới đây là một số ví dụ về ứng dụng phân cụm K-means trong thực tế:
Bệnh viện muốn bố trí đơn vị cấp cứu ở khoảng cách gần nhất với khu vực thường xuyên xảy ra tai nạn
Nhà địa chấn học nghiên cứu những khu vực từng xảy ra động đất trong vài thập kỷ qua để xác định khu vực có nguy cơ cao ở thời điểm hiện tại
3. Regressions
Regressions (Hồi quy) tạo ra mối quan hệ và tương quan giữa các loại dữ liệu khác nhau. Ví dụ, mỗi ảnh hồ sơ pixel thuộc về một người. Với dự đoán tĩnh (static prediction), hay còn gọi là dự đoán không thay đổi theo thời gian, học máy xác nhận cách sắp xếp pixel nhất định tương ứng với một tên và cho phép nhận dạng khuôn mặt (Ví dụ: Facebook đề xuất gắn thẻ cho ảnh bạn vừa tải lên).
Hồi quy cũng hữu ích khi dự đoán kết quả dựa trên dữ liệu ở hiện tại. Từ lâu, hồi quy thống kê đã được sử dụng để giải quyết nhiều vấn đề, chẳng hạn như dự đoán phục hồi của chức năng nhận thức sau đột quỵ, dự đoán sự rời bỏ khách hàng,...
Hiện nay, nhiều phân tích hồi quy được thực hiện hiệu quả và nhanh chóng hơn bằng máy móc. Hồi quy là một loại thuật toán học máy có cấu trúc, nơi con người có thể gắn nhãn đầu vào và đầu ra.
Hồi quy tuyến tính cung cấp kết quả đầu ra với các biến liên tục (bao gồm bất kỳ giá trị nào trong phạm vi). Hồi quy logic là khi biến phụ thuộc về mặt phân loại và các biến gắn nhãn được xác định chính xác.
4. Deep learning
Deep learning (Học sâu) tương tự như học máy. Trên thực tế, nó giống một ứng dụng học máy bắt chước hoạt động của bộ não con người. Mạng học sâu diễn giải dữ liệu lớn, cả phi cấu trúc và có cấu trúc, đồng thời nhận dạng các mẫu.
Máy tính học hỏi được càng nhiều dữ liệu, quyết định của nó sẽ càng chính xác. Dưới đây là một số ví dụ về deep learning trong thực tế:
Chatbots và trợ lý ảo: Trợ lý ảo như Alexa và Siri hoặc chatbot dịch vụ khách hàng trên các trang web khác nhau sẽ nhận yêu cầu, giải mã ngôn ngữ và đưa ra phản hồi như người thật.
Đặt giá thầu theo thời gian thực và quảng cáo theo chương trình: Quảng cáo hiển thị phụ thuộc vào việc mua không gian quảng cáo thông qua quy trình đặt giá thầu cạnh tranh. Cognitiv AI là một ví dụ về nền tảng học sâu tổng hợp dữ liệu nhân khẩu học của khách hàng, thời tiết, hàng tồn kho có sẵn, thời gian trong ngày và nhiều biến số khác để tạo thuật toán mua tùy chỉnh cho một thị trường mục tiêu cụ thể.
Công cụ đề xuất: Từ trang web du lịch như Booking.com và Expedia đến các nền tảng phát trực tuyến như Netflix và Spotify, công cụ đề xuất sẽ học hỏi từ hành vi mua hoặc sử dụng trong quá khứ để tùy chỉnh hoạt động tiếp thị. Có hai dạng công cụ đề xuất: Cộng tác và lọc dựa trên nội dung.
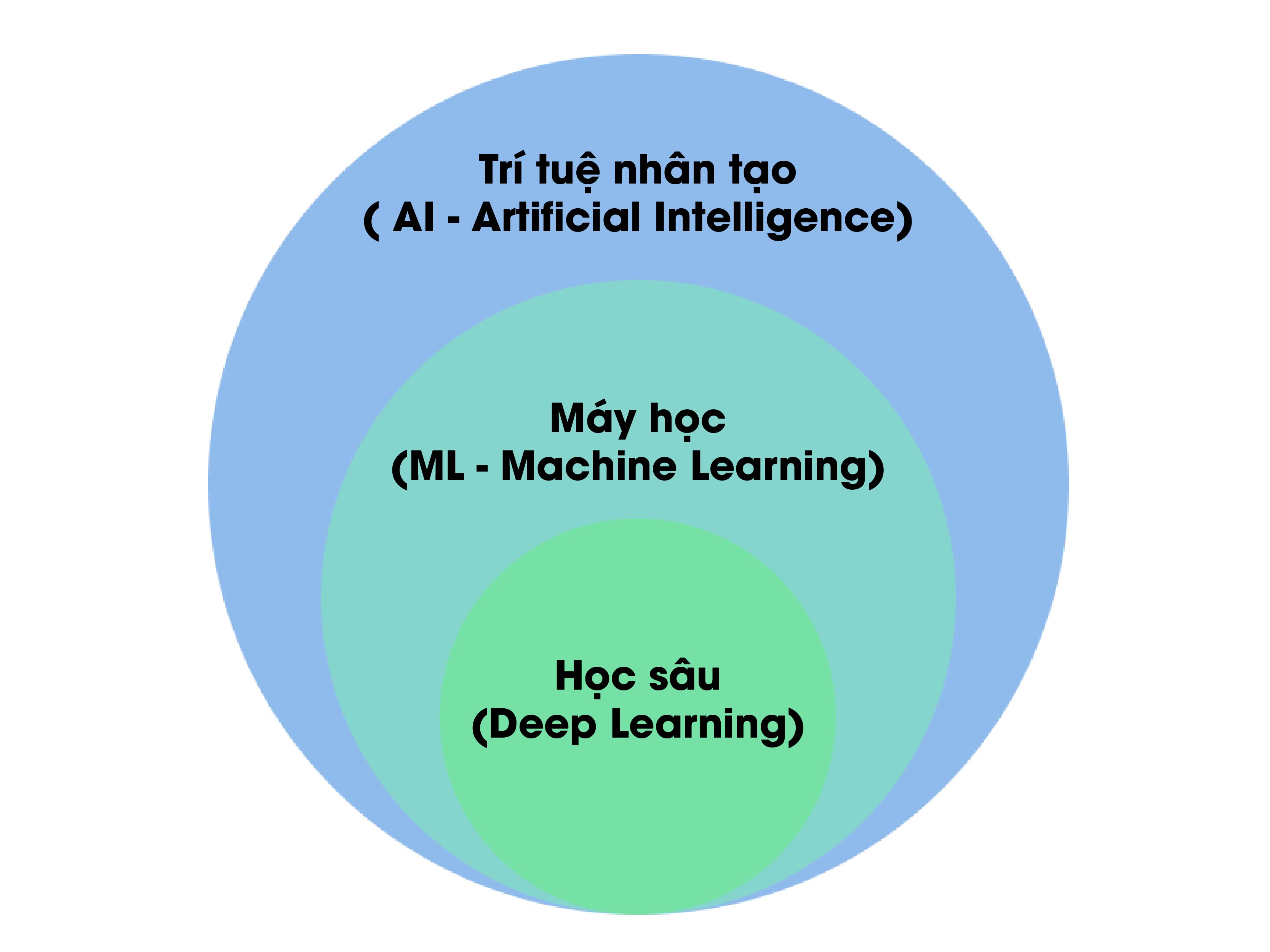
Mối quan hệ giữa AI, ML và học sâu - Ảnh: Internet
5. Neural Networks
Neural Networks (Mạng lưới thần kinh) có liên quan chặt chẽ đến học sâu. Nó tạo ra các lớp nơ-ron tuần tự giúp hiểu sâu hơn về dữ liệu được thu thập từ máy tính, góp phần đưa ra phân tích chính xác.
Mạng lưới thần kinh bao gồm nhiều lớp nút, nhận sự kích thích từ dữ liệu “kích hoạt”. Dữ liệu này sau đó được gán trọng số thông qua các hệ số, vì một số dữ liệu đầu vào có thể quan trọng hơn dữ liệu khác.
Nơ-ron thường có ba lớp khác nhau: Lớp dữ liệu đầu vào (input layer), lớp ẩn (hidden layer) chứa phép tính toán học và lớp đầu ra (output layer).
6. Natural Language Processing
Natural Language Processing (Xử lý ngôn ngữ tự nhiên) nằm trong lĩnh vực AI xử lý ngôn ngữ của con người. Đây là một thuật ngữ rất quan trọng trong lĩnh vực khoa học dữ liệu và học máy.
Thách thức đặt ra là lời nói của con người đôi khi không thể hiểu theo nghĩa đen. Có những hình thái lời nói, từ hoặc cụm từ cụ thể cho một số phương ngữ và văn hóa nhất định, cũng như câu có thể mang ý nghĩa khác nhau tùy theo ngữ pháp và dấu câu.
Tương tự như cuộc trò chuyện của con người, bộ xử lý ngôn ngữ tự nhiên cần sử dụng cú pháp (sắp xếp từ) và ngữ nghĩa để hiểu và đưa ra phản hồi chính xác.
Bước đầu tiên trong xử lý ngôn ngữ tự nhiên là chuyển đổi dữ liệu ngôn ngữ phi cấu trúc thành dạng mà máy tính có thể đọc được. Sau đó, máy tính gán ý nghĩa cho từng câu nhờ thuật toán và dịch ngược lại, thông thường sẽ ở dạng khác (Ví dụ: Chuyển lời nói thành văn bản hoặc từ ngôn ngữ này sang ngôn ngữ khác).
Xử lý ngôn ngữ tự nhiên hỗ trợ các ứng dụng dịch thuật như Google Translate, công cụ giao tiếp và cộng tác như Slack và Microsoft Word.
7. Machine Vision
Machine Vision/Computer Vision (Thị giác máy tính) là quá trình máy móc chụp và phân tích hình ảnh. Điều này cho phép chẩn đoán ung thư da bằng cách xem tia X và các hình ảnh y tế khác; phát hiện vi phạm giao thông theo thời gian thực; phát triển phương tiện tự lái;...
Có nhiều cách khác nhau giúp máy móc “nhìn thấy”: Thể hiện màu sắc bằng số, phân tách hình ảnh thành những phần khác nhau và xác định góc, cạnh và họa tiết. Khi máy thu thập và mã hóa thêm thông tin, chúng dần dần xem được bức tranh lớn hơn.
Xu hướng thị giác máy tính hiện nay bao gồm việc tích hợp vào Internet vạn vật (IoT - Internet of Things) công nghiệp để thu thập đầu vào năng suất, dữ liệu từ nhà máy cũng như các ứng dụng phi công nghiệp như thiết bị nông nghiệp tự động, máy bay không người lái,...
Máy học hiện đang là một trong những công nghệ nhận được sự chú ý trong ngành. Trên đây là tóm tắt về một số thuật ngữ xoay quanh máy học, hy vọng bạn đọc sẽ tham khảo để có thêm thông tin về lĩnh vực học máy nói chung và trí tuệ nhân tạo nói riêng.
Nguồn tham khảo:
https://www.springboard.com/blog/data-science/machine-learning-terminology/
![[ELCOM ITS] Inside ELCOM ITS: Cách các hệ thống giao thông thông minh được tạo ra](https://elcom.com.vn/storage/uploads/images/T9bk59vjsZOeOLnZd6MTL9aIlD8hjfdts1x0BhFU.png)
![[ELCOM ITS] Toàn cảnh bức tranh giao thông đô thị Việt Nam](https://elcom.com.vn/storage/uploads/images/r39s7ufmcggta29Taw5iGprfb4tMLb2beRmGsSBg.png)
![[ELCOM ITS] Lịch sử ITS Việt Nam: Hành trình thông minh hóa giao thông quốc gia](https://elcom.com.vn/storage/uploads/images/OPLZ1SxPQYi9Dzhztc48h0RHTeo4biTvTEhzBLeW.png)

